Building Research Driven Products: Optimizing for efficient value creation
I've spent about the last few months gathering my thoughts on product development and compiled them into this post. As a startup, we often hear all sorts of feedback from all walks of life (customers, founders, investors, advisors, etc.). The one thing we here almost universally is "move fast and break things" or some variation of the phrase followed by an example of another company that had "successfully" implemented this strategy. This works well for many startups but for any business that's building a foundational product, a product which acts as the foundation to others, in a new domain, this is probably too simplistic of an approach.
As an infrastructure company in Web3 - a brand new way of interacting on the web - we're a foundational product. We believe building our product using a research-driven strategy is the right approach. This differs from customer-driven product development in a few ways but for the most part overlaps on most principles. The one major principle difference though: Listen to customer feedback but don't let it drive product development. Our product development strategy is a result of analyzing data along with customer feedback to help build the foundation on which our, current and future, products and features can be built.
Some years ago I was given, what many in Silicon Valley consider, the bible for building and running a tech company, "The Lean Startup" by Eric Ries. It had 3 simple and easy-to-digest principles on how to successfully iterate on your product:
- Build: Create an MVP (minimum viable product) that allows you to test your hypothesis.
- Measure: Gather data and feedback to determine whether what you built works and whether you can build a sustainable business around it.
- Learn: Use the data you gathered to determine what to build next.
This approach made it easy for startups to have an internal framework they could use to quickly build and iterate on a product. The goal of any business is to generate profits and if you can quickly iterate on your product to increase your revenues, thereby increasing your bottom line, it's a no-brainer.
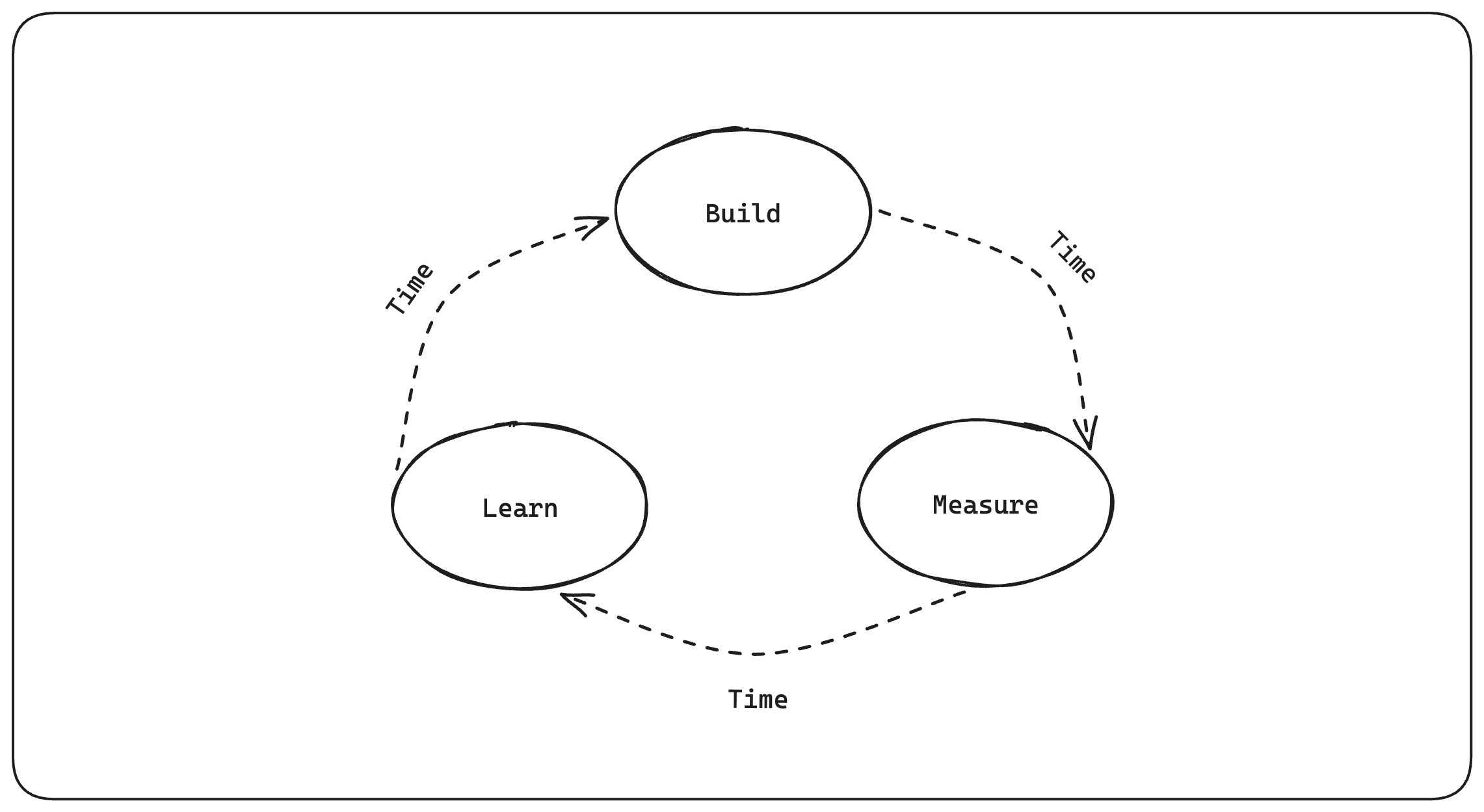 The Build-Measure-Learn feedback loop.
The Build-Measure-Learn feedback loop.
This feedback loop alone is not a problem, but when mixed with the "move fast and break things" mantra, it can lead to less-than-ideal outcomes in the long run. This framework was taken out of context and created a whole class of startups that, almost solely, focused on increasing metrics, not necessarily the long-term sustainable profitability of a business.
What I've observed is the time in between each of the steps laid out is elastic. This means it can take as little or as long as your iteration cycle takes. There's no real strategy on how to manage the time between each step of the iteration cycle aside from "move fast." For us, the goal is to reliably deliver products and features while building and maintaining a solid foundation. When thinking about our iteration cycles, I try and keep these few things in mind:
- Anticipate problems & get ahead: Try and anticipate problems that will be introduced as a result of this iteration cycle and get ahead of it. Often, this is very hard to do as most bugs are unintentional (:p) but when you're able to anticipate potential issues, such as scaling, absent error propagation, data inconsistency issues, etc., it helps immensely to get ahead of them.
- Never forget the grand vision: Creating a new feature or an adjacent product line should never come at the cost of the longer-term vision of the business. This can be incredibly hard to do as the customer is never wrong.. except for when they are. Be mindful not to accidentally create a "Frankenstein" product. Identify those moments and make decisions accordingly.
- Uptime/reliability is the #1 feature: As a foundational business, never forget the number one feature you offer customers is uptime and reliability. It is the single most important feature of a foundational business yet it's often overlooked and, at times, sacrificed.
When thinking about the long-term sustainability of our business, we need to lay the foundation for products and features that we know our developers will need in the not-so-distant future.
So the goal is sustainable profitability. To understand how best to achieve it, we need
to understand a startup's
iteration_efficiency factor. This factor represents how efficient a product
iteration cycle is. The idea being,
creating more efficient iteration cycles will lead to more efficient value
creation. However you define your startup's iteration_efficiency factor internally
is completely up to you. For example, it can be the length of each iteration, how many
iterations you're able to achieve within a certain period or how many features you can
ship within each cycle. All 3 are somewhat correlated but it's important to know what
you're optimizing for as it varies from business to business.
A startup's iteration_efficiency factor is dynamic and will likely change
between iterations. Some cycle's iteration_efficiency will be better than
others. That's ok so long as the average over some N iterations is trending in the right
direction. For us, we're typically constrained by the ability to deliver products and
features promptly while maintaining a foundation that can last through future iteration
cycles. For this reason, our iteration_efficiency is a result of compounded
technical debt that we accrue or amortize over our iteration cycles.
When I first tried to measure or estimate an iteration cycle's resulting technical debt,
I was unable to reliably. McKinsey refers to technical debt as a "digital dark matter" and I tend to agree. If you can't measure a value reliably, how can you use it in
some formula? It's not actually an exact measurement of technical debt that needs to be
observed. It's the delta that's needed to calculate our startup's
iteraction_efficiency. It's based solely on an internal mental model you
consistently follow and tune over time. Only you can know how much effort you saved, or
added, in future iteration cycles. My mental model is the following:
| Time Added (+) or Saved (-) | Technical Debt Delta |
|---|---|
| +1 Month | +50% |
| +7 days | +10% |
| +24 hours | +1% |
| -24 hours | -1% |
| -7 days | -10% |
| -1 Month | -50% |
Yes, it's not a linear scale. For us, technical debt's effect is exponential. One day's
worth of technical debt added to future iteration cycles is not as impacting as adding,
say, a week or a month. That kind of technical debt can severely hinder our ability to
continue to deliver products & features in a timely manner. Given this arbitrary
internal mapping of technical debt time saved/added to some delta, we can now deduce an
iteration_efficiency going forward. If we were to translate this into code,
it'd look like:
# iteration_efficiency
e = 1
# natural_iteration_efficiency_factor constant:
# we assume that with every iteration cycle, there's
# some natural gain in iteration_efficiency
EN = 1.15
while True:
e = (e * EN) * (1 - technical_debt_delta)
With this mental model of iteration_efficiency, we can now try and find
practical ways that can assist in making our iteration cycles yield a negative technical
debt delta. As mentioned previously, as an infrastructure business we need to deliver
products and features while building and maintaining a solid foundation. For this
reason, we modified the Build-Measure-Learn feedback loop slightly to optimize for
research-based product development. Here's what it looks like:
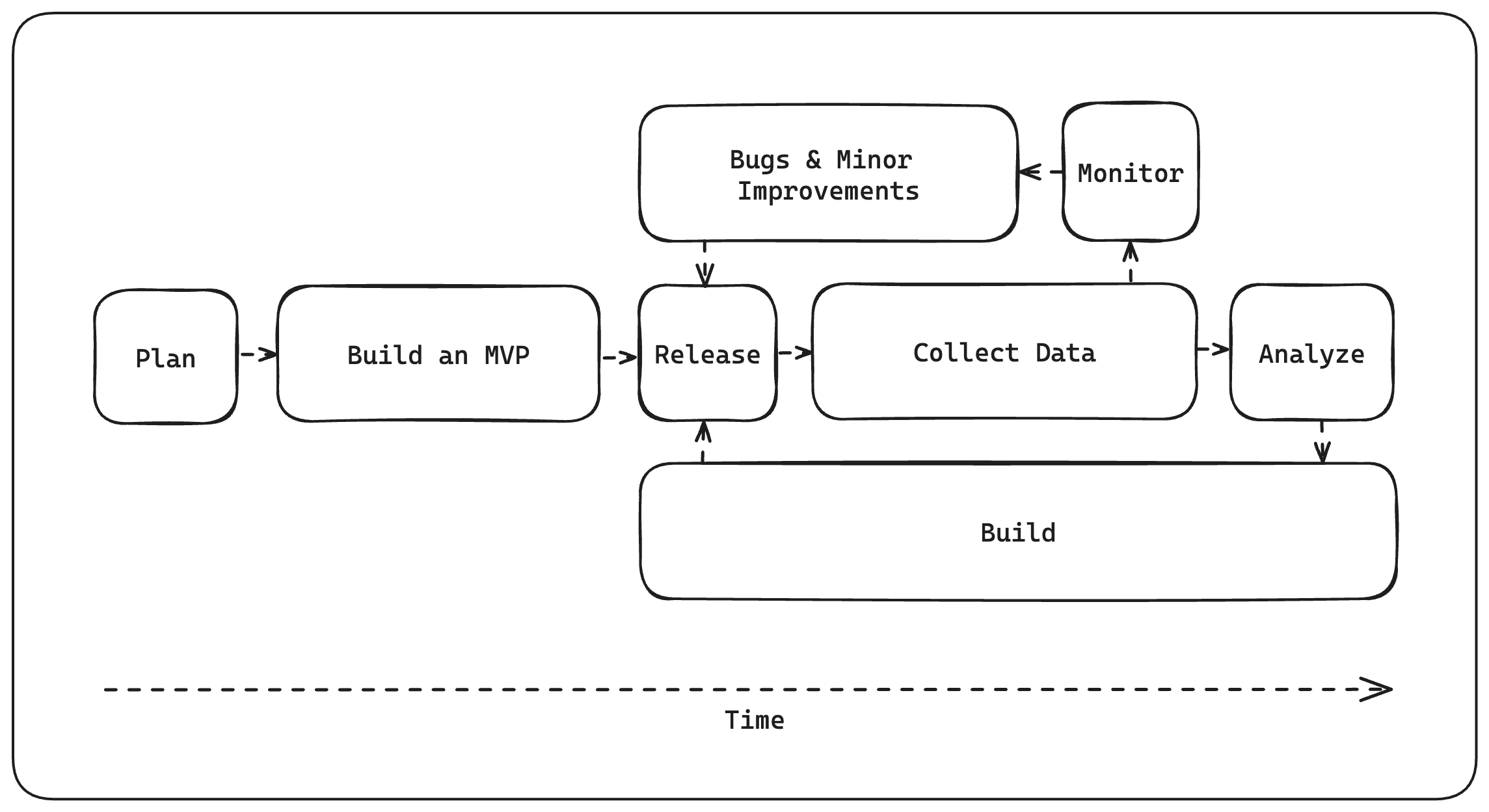 The Build-Collect-Analyze feedback loop
The Build-Collect-Analyze feedback loop
This is a visual representation of how we construct our iteration cycles. Each step plays an important role and more importantly, is timed relative to other steps. It gives us a mental model of what we should be focusing on as a team at any given time. It also helps individual team members know what he/she should be working on and for how long, given their role in this feedback loop. This model is what we use, as a foundational product, but I'm sure it can apply to other products with some fine-tuning.
Plan: This phase is step one in our Build-Collect-Analyze feedback loop. It's the step in which you identify the problem and hypothesize a solution. This step sets in motion what data you'll be collecting. It should be relatively quick as you want to get the product in front of customers soon so that you can start to collect data.
Build an MVP: When thinking about an MVP (or minimum viable product), we need to focus on how we can minimally solve our customers' problems while collecting data to analyze for our first true iteration cycle. Focusing more on the data and less on features is what I'd generally suggest as it's more important to know what to build in the future rather than delivering a "feature-packed" product on the first go.
Release: Timing is key to any business and releasing a product at the right time is important. It will come to you.
Collect: Data, data and more data. If you're not collecting data on how your product is being used by your customers, you're not able to complete the next steps accurately, analysis and monitoring. One thing to note, you must collect data over a meaningful period. If you fail to do so, you won't have a sample size large enough to run a true analysis. This can be painstaking as while your competitors continue to ship, you have to remain disciplined and stay the course.
Analyze: With the data you've collected over some meaningful period, analyze it and start to surface insights that are not necessarily obvious. This is arguably the most important step in our feedback loop.
Build: This is the true "build" step. This build step is not just solving your customers' problem but, using insight gathered by analyzing the data you've collected, is taking the next step in your startup's grander product vision.
And
Monitor: To ensure your current release is performing as intended, it's important to set up your data pipeline to allow for continuous monitoring. This will aid in the next step.
Improve: Continuously improve and fix minor bugs. You don't want your current release to suffer due to bugs and obvious improvements while trying to collect data over a meaningful period. It's important to continue to push these minor improvements because, more often than not, they will also aid in collecting data accurately.
Then back to Release
This differs from the Build-Measure-Learn feedback loop in a few ways. In the Build-Measure-Learn loop, there's no distinction between the Analyze-Build and Monitor-Improve stages. Both need to happen in parallel. One aids in the immediate term and the other is crucial to the grander end-state product vision. Also, as mentioned previously, the Build-Measure-Learn loop doesn't really provide us with any framework on how certain steps are timed relative to one another. The Build-Collect-Analyze feedback loop generally does have longer iteration cycles initially. This is due to the "Collect" step which emphasizes collecting data over some meaningful period which then allows us to derive insights in our Analyze step reliably.
Harvard Business Review posted an article titled "What the Lean Startup Gets Right and Wrong" where they stated "The focus on getting fast feedback from customers to Minimal Viable Products makes startups prone to aim for incremental improvements, focusing on what customers want today, rather than trying to see ahead into the future. Additionally, a lot of research, such as that done by Clay Christensen on disruptive innovation, shows that novelty is often initially disliked by customers. Seeking external validation from early customers can thus be even harder if you have a breakthrough idea than if you have an incremental, but easily explained, product."
Additionally, the article stated "it doesn't ask the most important one (question): what
is your hypothesis about the world based on your unique knowledge and beliefs? ...there
is no roadmap to get to that end-state in the Lean Startup Method." I think the
Build-Collect-Analyze feedback loop helps in keeping your startup's end state in view.
This in turn helps us keep the focus on making our iteration cycles'
iteration_efficiency as high as possible.
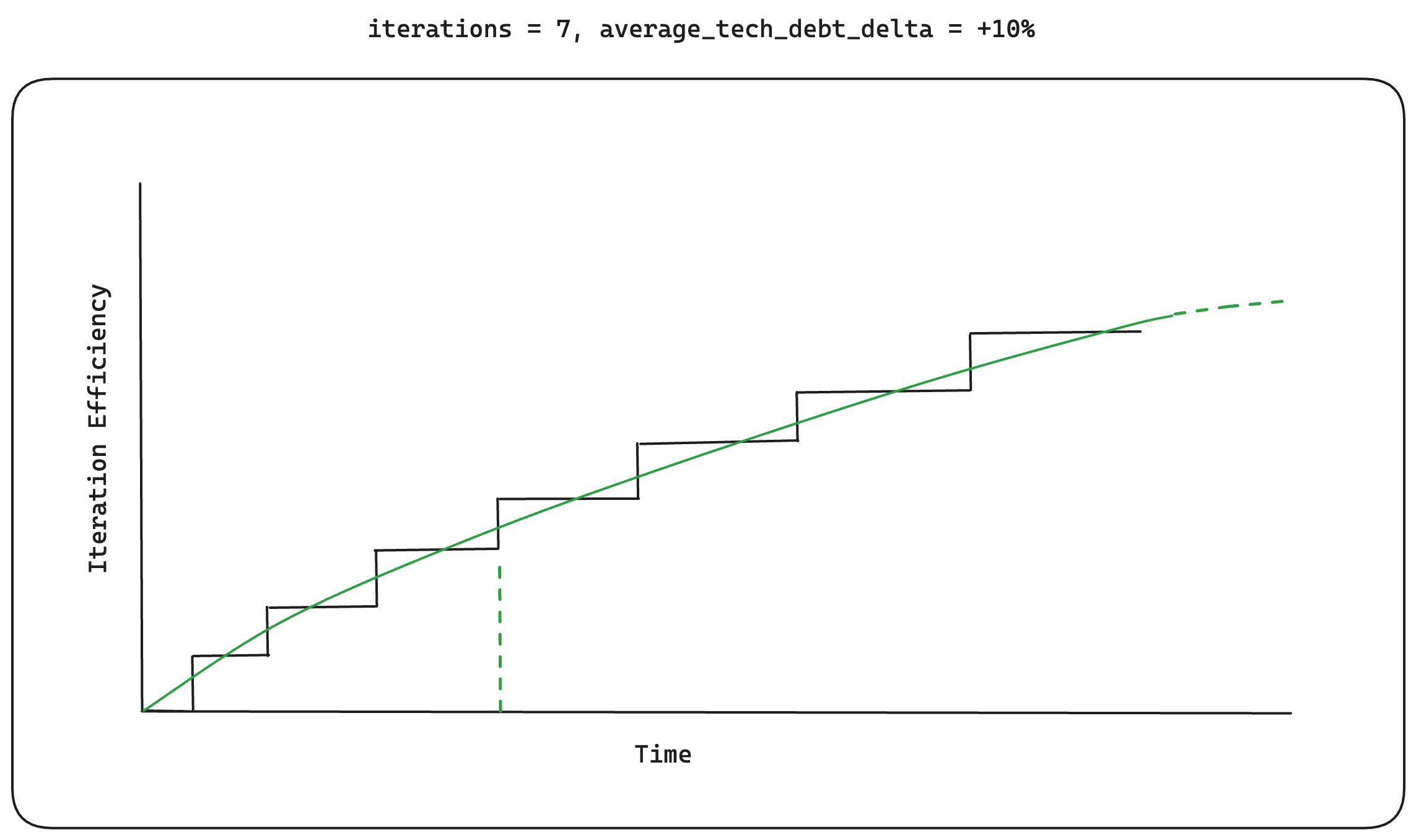 An average of +10%
An average of +10% technical_debt_delta over 7 iteration cycles
Since the focus of the Build-Measure-Learn feedback loop isn't improving
iteration_efficiency, we assume that the cycles produce, on average, an
increased technical_debt_delta. Again, for some startups, this may be
completely fine. The benefit of this feedback loop is that you're moving fast. Initial
iteration cycles are shorter as you're not collecting data over a meaningful period.
Given an average technical_debt_delta of +10%, we can reach the 3rd level
of our iteration_efficiency in a short amount of time as shown above.
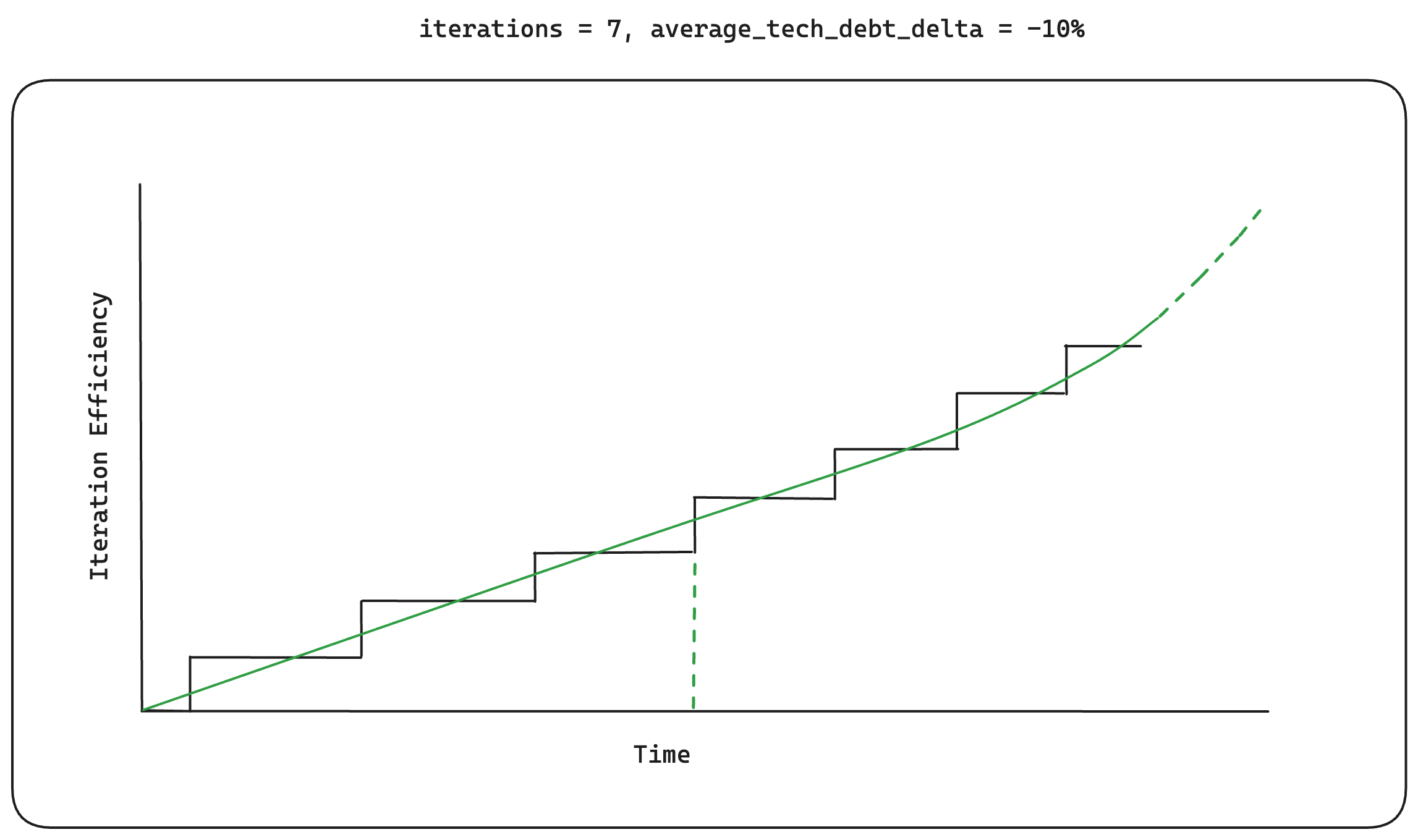 An average of -10%
An average of -10% technical_debt_delta over 7 iteration cycles
The Build-Collect-Analyze feedback loop focuses on improving
iteration_efficiency from the very beginning. This means longer initial
iteration cycles. We assume that the cycles produce, on average, a decreased
technical_debt_delta as you're collecting data over a meaningful period and
then analyzing it before jumping to the next build stage. Given an average
technical_debt_delta of -10%, we can reach the same 3rd level of
iteration_efficiency, but takes a longer amount of time to get there. At
first, this doesn't seem to be the best approach but when you zoom out further the
results begin to look interesting.
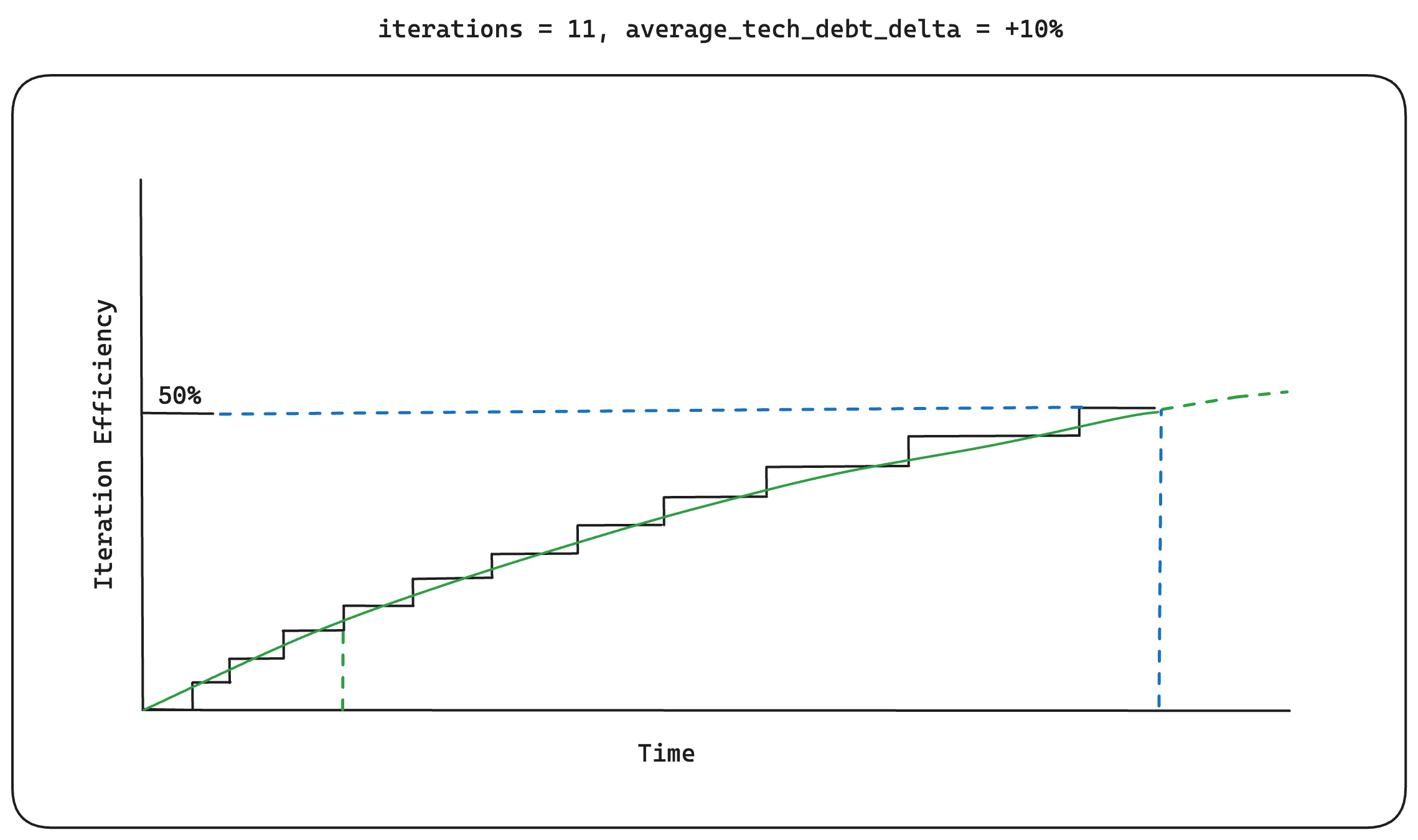 An average of +10%
An average of +10% technical_debt_delta over 11 iteration cycles
Looking at the graph over 11 iterations paints a different picture. With the
Build-Measure-Learn feedback loop, we can see that initial iteration cycles, being short
and sweet, allow us to reach a higher level of iteration efficiency sooner but then we
start to plateau very quickly. We're able to achieve the 50%
iteration_efficiency target with our iterations taking a little bit longer
in each cycle. The initial iteration efficiency gains are eventually meaningless and we
begin to see negative results when comparing to the average
technical_debt_delta value of -10%, using the Build-Collect-Analyze
feedback loop, below:
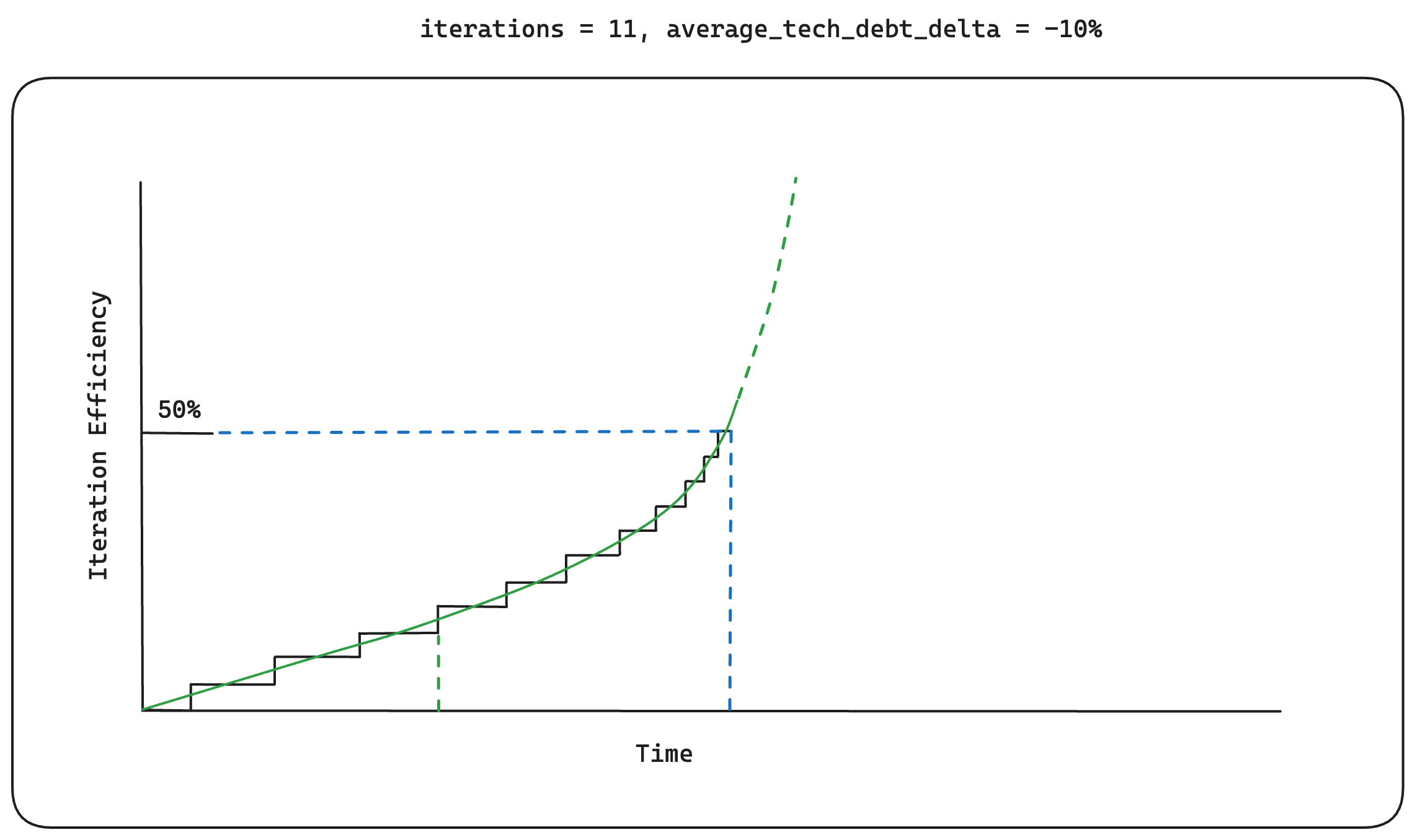 An average of -10%
An average of -10% technical_debt_delta over 11 iteration cycles
With the Build-Collect-Analyze approach, we can see the more we iterate, the faster we
can hit our iteration_efficiency targets. This in turn allows for
more efficient value creation, which I'd argue is the most important metric for
an infrastructure startup building a foundational product. Your startup's unit economics
need to factor in your competitors' efficiency gains over time. At the end of the day,
as an infrastructure business, it's a race to the bottom.
When I initially struggled to accept the "move fast and break things" advice I heard all too often, I tried to narrow in on why exactly. I knew we were a research heavy organization within every facet of our business and I strongly believe this approach is the correct way to build a foundational product. Naturally, I googled "building research driven products" and found very little posts/articles on the matter. Most research/posts on the matter pointed to customer-driven product development strategies. I think this points to a broader problem in the Silicon Valley startup ecosystem, but that's a discussion for a future post.
You can't build a research-driven product alone, you need a team that can continuously aid and support in that process. We've hired some of the most talented folks who help bring this Build-Collect-Analyze feedback loop to life. Each team member, whether they're on our engineering, research, growth/BD, or operations team, understands the importance of data and analysis. This has to resonate at the core of every member of your organization, I can't stress this enough. I leave you with this quote:
Any fool can know. The point is to understand.